概要
KubernetesやDockerではポッドやコンテナの使用CPU数を簡単に変更することができます。簡単が故に設定さえしてしまえばそのシステムはそのリソースを使用して稼働しているものと誤解しがちです。この文章ではKubernetesと簡単なプログラムを使ってリソース割り当てとスレッドの関係について紐解いていきたいと思います。
環境
docker desktopのkubernetes機能を使います
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.5", GitCommit:"aea7bbadd2fc0cd689de94a54e5b7b758869d691", GitTreeState:"clean", BuildDate:"2021-09-15T21:10:45Z", GoVersion:"go1.16.8", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.5", GitCommit:"aea7bbadd2fc0cd689de94a54e5b7b758869d691", GitTreeState:"clean", BuildDate:"2021-09-15T21:04:16Z", GoVersion:"go1.16.8", Compiler:"gc", Platform:"linux/amd64"}
kube上のリソース表示にmetrics-serverとk9sをつかっています。
詳細
KubernetesやDockerでは、立ち上げるコンテナにCPUを割り当てることができます。Kubernetesの場合、稼働しているポッドにいくらCPUを積んでも性能が上がらないなんてことはなかったでしょうか。もしかするとそのCPU、無駄かもしれません。
「そのプロセス、本当にマルチスレッドですか?」の問いに答えることが重要です。特に意識せず開発されたシステムであれば通常はシングルスレッドでしょう。その場合には最大でも1000mi cpu(1 cpu)以下が適切な設定値となります。それ以上の設定値は意味がありません。
Kubernetesの場合、request.resources.cpuなどに設定を入れることができます。これで常にポッドがそのcpu数で動作していると思われがちですが、正確には「コンテナが並列に実行できるスレッド数(そのスレッド数で実行しているとはいってない)」というべきでしょうか。
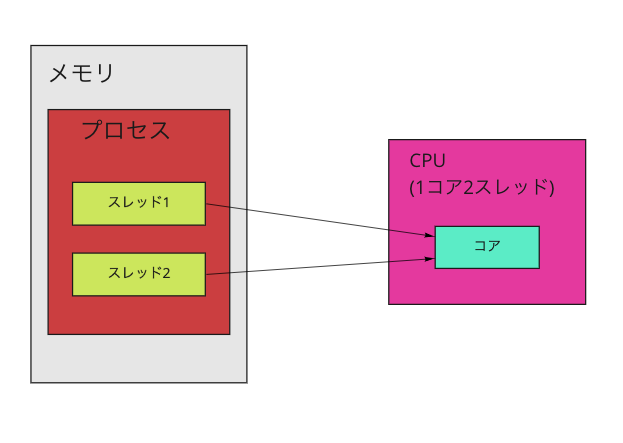
以下の図を見てみてください。左側にメモリ、右側にCPUを表しています。プロセスやスレッドは実行するとメモリ上に展開されます。ここでコンテナに2cpuを割り当てたとします。これは一度に2スレッド並列に処理する能力がこのコンテナに与えたことを意味します。メモリ上で1プロセスに2スレッドが展開されているため、無駄なくcpuリソースを使用できていると言えます。
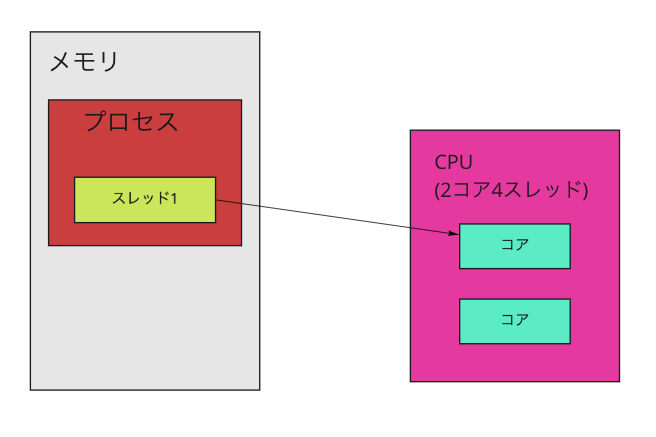
スレッドを意識していないプロセスを考えてみます。その場合には以下のように1プロセスに1スレッドがメモリ上に展開されます。簡単にフルスクラッチで書いた世の中の大体のプログラムはこのような形になるでしょう。ここで4000mi cpuをこのコンテナに割り当ててみます。3000m cpuは使われずに無駄になってしまいました。
ここから少し実験してみます。まずは1000m cpuをコンテナに割り当て適当に無限ループのプロセスを稼働させてみます。

このようにCPUが限界の1000m cpu付近まで使用されていることがわかります。
ではこのコンテナに2000m cpu割り当てて同じことをしてみます。

やはりcpuが1000m以上は利用されず、resuestに対するパーセンテージも50%を上回ることはありません。
先述の通りコンテナ上で動作しているプロセスがシングルスレッドで動作するものだからです。
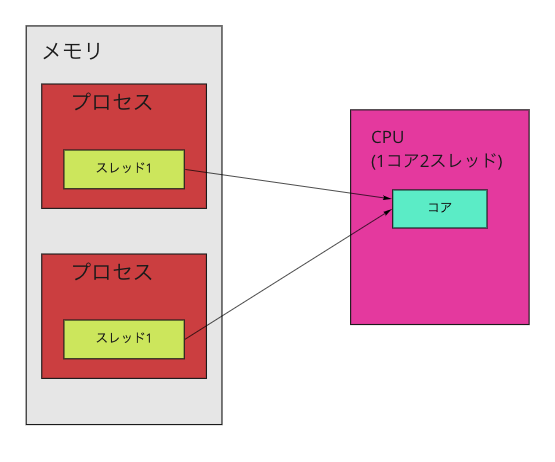
同じプロセスをもう一つ走らせてみると簡単に1000mi cpuを超えることができます。

これは図にすると以下のような状態です
ではもう一例、次は1プロセス2スレッドで1000mi cpu超えを試してみます。以下のようなjavascriptを利用します。
File: master.js
const { spawn, Thread, Worker } = require("threads");
(async () => {
const auth1 = await spawn(new Worker("./workers/auth"))
const auth2 = await spawn(new Worker("./workers/auth"))
const hashed1 = await auth1.doloop("Super secret password", "1234")
const hashed2 = await auth2.doloop("Super secret password", "1234")
})()
File: workers/auth.js
expose({
doloop(password, salt) {
while (true) {
console.log('foo')
}
}
})
このやり方でも1000mi cpuを超えることができています。

ちなみに1000mi cpuしか割り当てずに2スレッドのプロセスも動作は可能でした。しかしながら2スレッドを前提にしているプロセスなのであれば唐突に重くなったりエラー終了したりすることを避けるためにも2000mi cpuを割り当てるべきでしょう。クラウドネイティブなアプリケーションであればスレッドを数を環境変数で外から設定できるようにしてpodのenvとcpu設定を合わせるように意識することは重要と考えます。
またマルチスレッドではないプロセスのコンテナに対して無闇に1000mi cpu以上わりあてないという点も無駄なお金を使わないためにも重要です。